
Qui, dans sa vie, n’a jamais souhaité retenir à jamais certaines notions ? Qui n’a jamais rencontré des problèmes dans la mémorisation de ses cours ? Vous avez peut-être déjà vu passer des publicités sur divers réseaux sociaux à propos de méthodes magiques pour “tout retenir sans effort”, nous traiterons aujourd’hui d’un logiciel libre permettant — réellement 😉 — de “tout retenir sans effort” — ou presque. Cet article sera surement moins technique que d’habitude, faisant plutôt appel à des notions de neurosciences, mais rassurez-vous, aucun prérequis n’est nécessaire pour aborder celui-ci !
Le logiciel dont je vous parlais en introduction est nommé Anki, afin de comprendre son fonctionnement, intéressons-nous d’abord à la façon dont notre cerveau traite, et surtout, stocke les informations.
🧠 Un peu de neurosciences
📦 Stockage
La mémoire, voici donc un concept bien obscur, premièrement, il faut savoir que l’on distingue habituellement cinq types de mémoire, chacun de ces systèmes communicant avec les autres, nous ne nous intéresserons qu’à deux d’entre eux, pour les plus curieux, une description plus détaillée des cinq types est disponible dans la bibliographie en bas de cet article.
- La mémoire de travail (aussi appelée mémoire à court terme) : Ce “type” de mémoire ne dure que quelques secondes, sans elle, vous ne pourriez retenir de quoi traite cette ligne de texte, ni même retenir un numéro de téléphone quelques secondes.
- La mémoire sémantique : C’est celle qui nous intéressera le plus ici, elle permet de retenir tous nos “savoirs”, la date de la bataille de Marignan, la traduction de “I Learned” ou les paroles du dernier titre de votre artiste préféré-e.
Quand on cherche à retenir une information, on va donc tenter de faire passer une information de la mémoire à court terme vers notre mémoire sémantique.
Concrètement, quand une information arrive dans le cerveau, elle est encodée par celui-ci, il parait évident que lesdites informations ne sont pas encodées sous forme binaire comme dans nos ordinateurs, sous quelle forme le sont-elles ?
Pour répondre à cette question, il faut d’abord faire un tour dans le fonctionnement de notre cerveau.
Les informations de la mémoire sémantique n’ont pas de lieu de stockage à proprement parler, elles sont stockées au niveau des neurones un peu partout dans le cerveau. Un neurone, ça ressemble à ça, le schéma présent ci-dessous n’est pas complet, il ne présente que les informations qui nous intéressent ici.
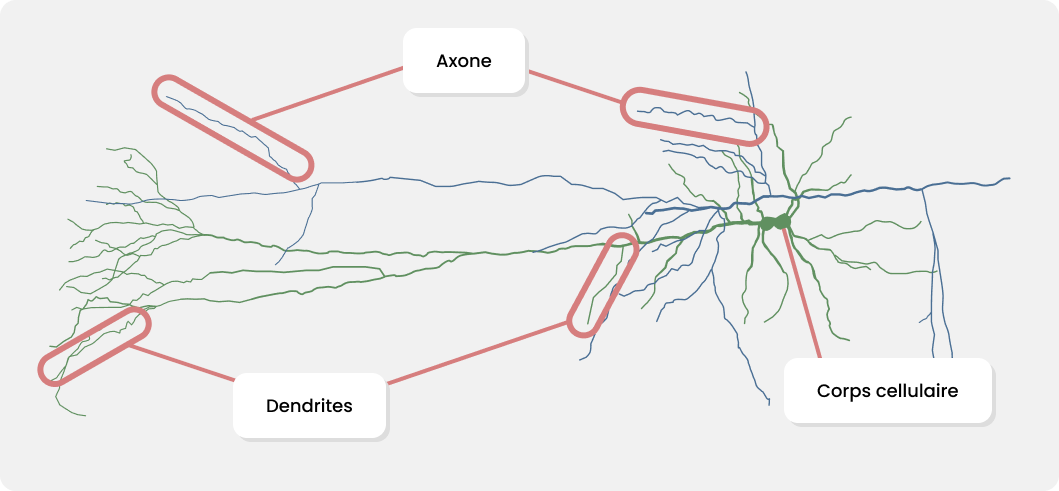
Bon, une image de cellule comme ça, ce n'est pas bien parlant, mais je vous assure que celle-ci a plus d’une particularité intéressante 😄. Comme vous pouvez le voir, un neurone est doté de nombreuses “branches”, appelées dendrites et axone dans lesquelles peut circuler un courant électrique, et d’un “centre” appelé “corps cellulaire” ou “soma”. Sur ce schéma, les dendrites sont les branches vertes, tandis que les bleues sont les axones. Sur ces branches, des dizaines d’autres neurones viennent s’accrocher, la région où ces cellules se lient est appelée synapse. Le courant électrique qui parcourt le neurone entre par les dendrites et sort par les axones.
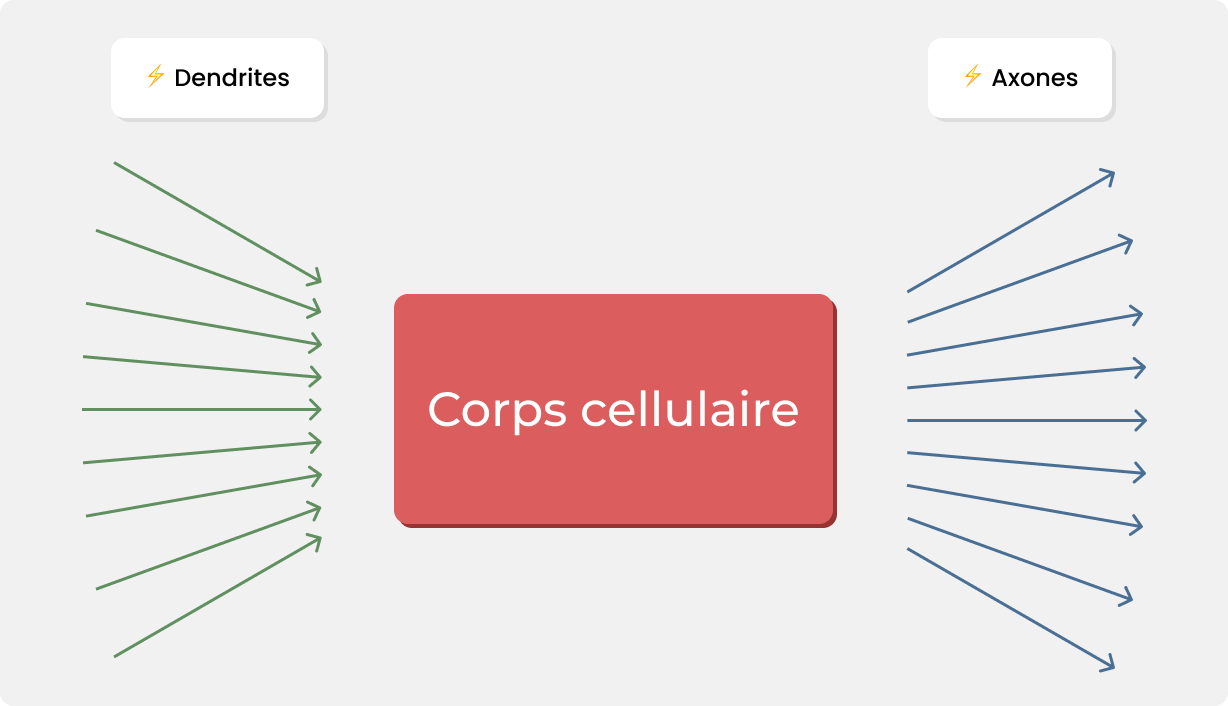
Un neurone tout seul n’est capable de rien — ou presque — c’est cet immense réseau qui permet nos capacités cognitives. Chaque petit sous réseau qui contiendrait une information est appelé engramme.
Petit avertissement, l’étude du fonctionnement du cerveau est un champ de recherche en évolution constante, les informations présentées ici ne représentent que de l’état de la recherche scientifique à date de publication.
Pour encoder une information — i.e “moduler” le signal électrique qui parcourt un neurone —, les neurones disposent de trois leviers, le premier est le placement de la synapse (rappelez-vous, c’est le nom donné à la région où se lient une dendrite et un axone !) sur la dendrite, l’endroit par lequel le signal passe d’un neurone à l’autre. Plus la synapse est éloignée du corps cellulaire, plus le signal va faiblir.

Le second levier est la force des synapses, des ions calcium peuvent être lâchés au niveau de la synapse, et ainsi changer la force de ces dernières.
Le troisième levier est la capacité des synapses à faire varier leur force, c’est un fonctionnement assez complexe que nous ne détaillerons pas ici, mais pour faire simple, l’axone va lâcher certaines molécules au niveau de la synapse, ce qui va avoir pour effet de modifier la puissance avec laquelle est transmis le signal.
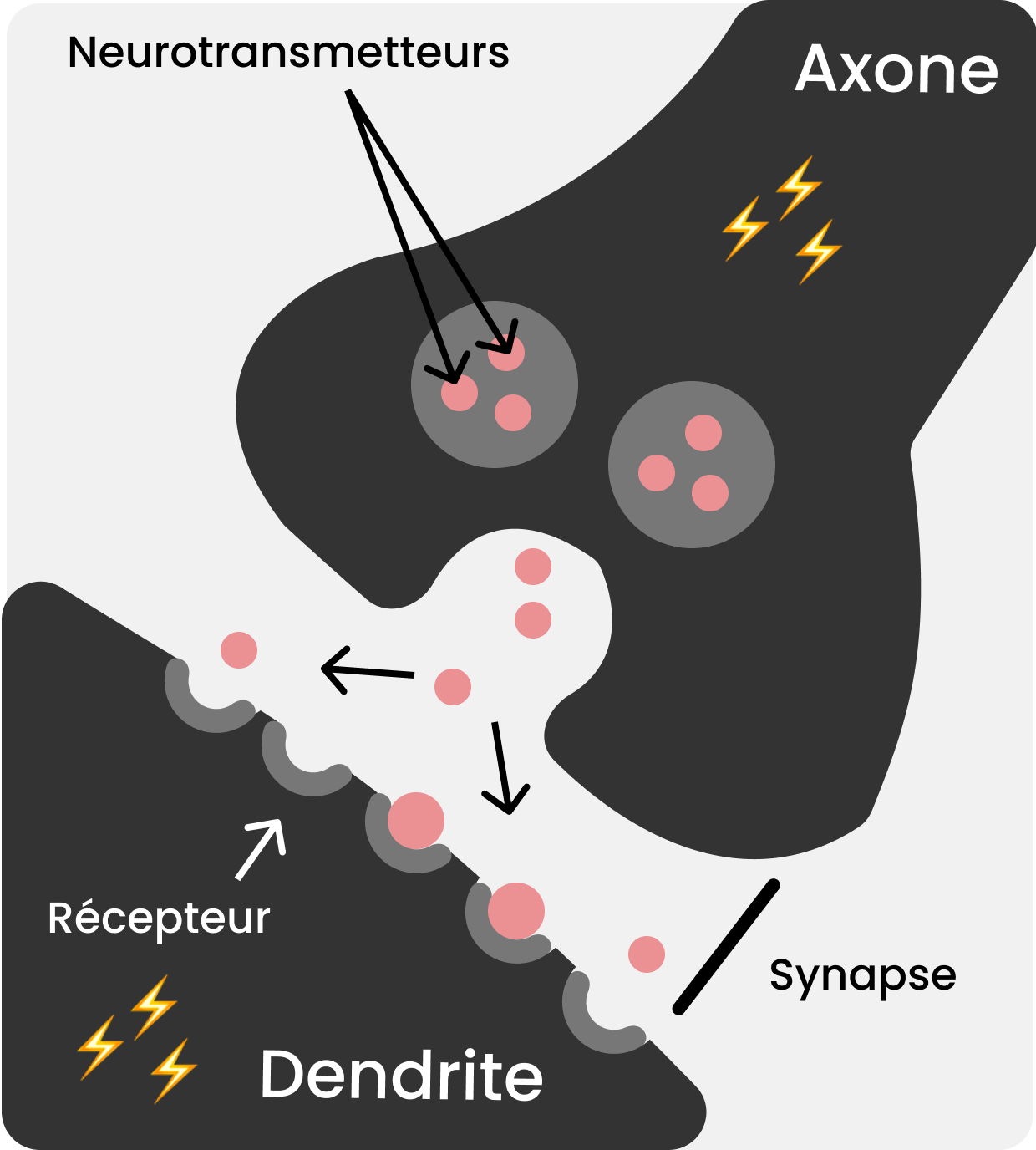
Il existe enfin un dernier levier, d’après certaines études les dendrites pourraient transformer le signal de façon non-linéaire, le mot fait peur, mais ce n’est pas si compliqué, cela veut simplement dire que la puissance du signal ne serait pas simplement multipliée par un certain nombre (rappelez vous de vos cours de maths 😛, une fonction linéaire, c’est une fonction exprimée sur la forme f(x) = m × x), mais que cette modification pourrait différer en fonction du signal en entrée.
Grâce à ces trois leviers, les neurones sont en capacité d’encoder des informations, et elles le font d’ailleurs bien mieux que n’importe lequel de nos ordinateurs !
🤔 Oubli
On oublie tous des informations, chaque seconde, l’oubli est un processus naturel auquel certaines personnes (amnésiques notamment) sont plus confrontées que d’autres. Certaines études suggèrent que ce serait la quantité d’une certaine protéine (appelée GluA2) qui dirigerait le déclenchement de l’oubli, il a par exemple été prouvé que retirer le récepteur de la protéine GluA2 permettait d’empêcher l’oubli d’avoir lieu dans la mémoire à long terme, dans une moindre mesure, la présence de cette protéine baisserait la force de la synapse, une synapse avec une force trop basse ne saurait de fait être activé, une certaine quantité de cette protéine permettrait donc de baisser suffisamment la force de la synapse afin de créer un oubli total. La présence de la protéine GluA2 n’est pas le seul mécanisme, Tomás J. Ryan et Paul W. Frankland écrivent dans un récent article (auteurs que je remercie par ailleurs de m’avoir envoyé leur article qui m’a en partie permis d’écrire celui-ci !) la phrase suivante, qui résume bien le fonctionnement des mécanismes de l’oubli :
We therefore propose that synaptic weight changes, leading to reduced engram cell accessibility, are a general (but perhaps not ubiquitous) mechanism of forgetting.
Vous remarquerez qu’il n’est ici jamais mention de la destruction d’un quelconque engramme (un engramme, pour rappel, c’est un petit réseau de neurones qui stocke une information précise), ils sont simplement rendus inaccessibles. Quand on oublie une information, il semblerait ainsi qu’elle ne soit jamais vraiment supprimée de notre cerveau, qu’il en reste toujours la structure neuronale, mais que celle-ci soit juste rendue inaccessible.
Maintenant, on a une idée de comment notre cerveau fait pour oublier des informations, mais ce qui nous intéresse le plus, c’est pourquoi, comment notre cerveau choisit quels engrammes il doit supprimer.
L’oubli aurait tout d’abord un rôle adaptatif, c'est-à-dire qu’en dégradant volontairement une information, on permet au cerveau de mieux “généraliser”, par exemple, un animal est attaqué un jour où il pleut, il y a 5 oiseaux qui chantent, l'animal qui l'attaque est un guépard, celui-ci a 94 taches noires sur son pelage, une oreille plus petite que l’autre, et plein d'autres détails. Le cerveau va dégrader l'information pour ne garder que "l'animal est beige avec des taches noires sur son pelage, il fait deux fois ma taille, il est dangereux" de sorte que l'animal déclenche la peur pour toutes les situations durant lesquelles il rencontre un guépard, même si ce n’est pas exactement le même.
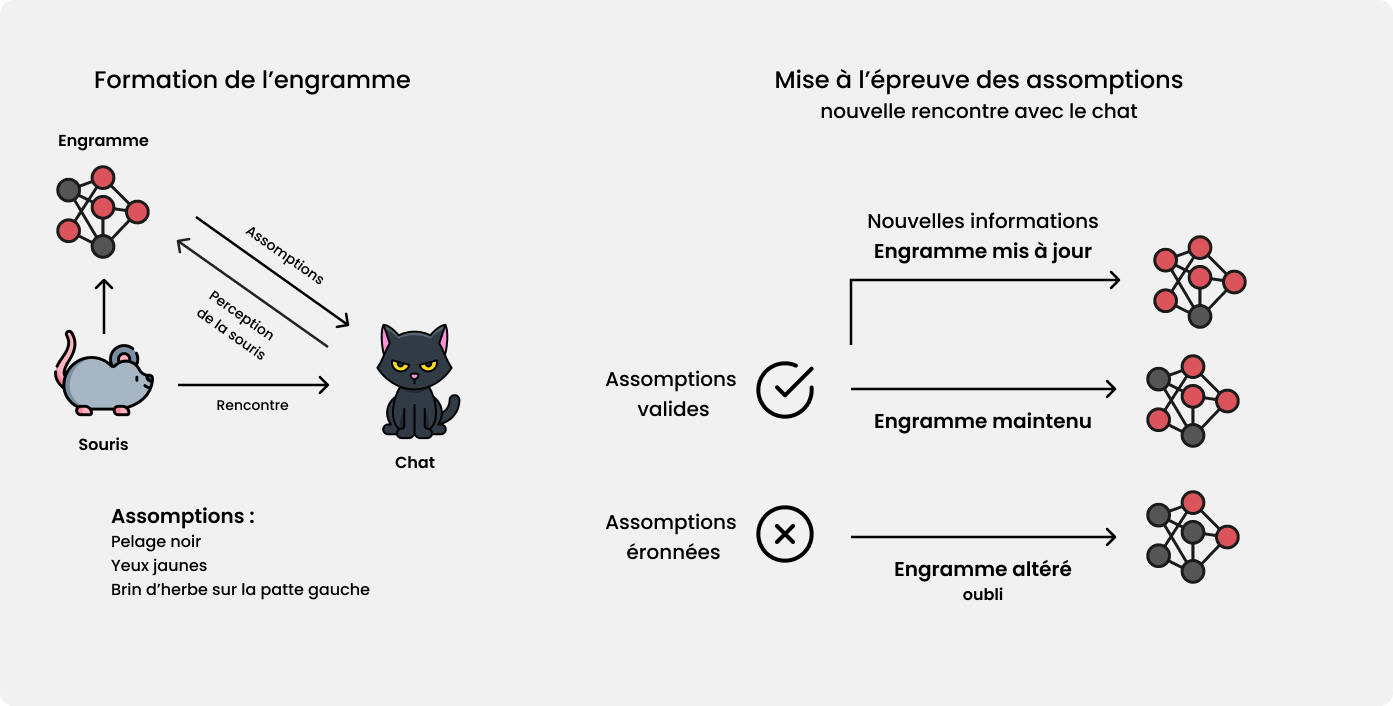
L’oubli est aussi dirigé par des paramètres dû à l’environnement du sujet, en clair, si une souris rencontre un chat pour la première fois dans son environnement, un engramme va être créé, son cerveau va faire des asomptions, des prédictions sur certains caractères qu’il devrait retrouver la prochaine fois qu’il croise un chat. Si ces prédictions s’avèrent vraies, l’engrame est maintenu, voir mis à jour si de nouvelles informations sont ajoutées. Cependant, si les prédictions s’avèrent fausses, le processus d’oubli est alors déclenché et l’engrame est altéré.
Il existe aussi un oubli “automatique”, après un certain temps sans qu’une information soit consultée, le cerveau fait “du ménage”.
🚀 Optimisation de l’apprentissage
On le sait tous-tes, la durée de rétention varie en fonction du type d’information stocké — on oublie facilement notre repas de la semaine dernière, mais pas ce super plat qu’on a mangé au restaurant il y a trois mois — il est attesté que plus un engramme contient de neurones différentes, et donc de connexion, plus il sera facile pour nous d’aller ensuite rechercher l’information contenue dans cet engramme. On peut ici conclure que si, par exemple, on veut apprendre la traduction de “chat” en anglais, afin de mieux s’en rappeler, il faudrait, durant l’apprentissage, “relier” cette notion à un maximum d’éléments, la prononciation du mot, un son de miaulement, une photo de chat etc.
On sait aussi que quand notre cerveau choisit de maintenir un engramme, après validation des assomptions faites, le temps avant que ne se déclenche l’oubli “automatique” est réduit. Ceci a été nottament illustré par un pionnier du domaine, Hermann Ebbinghaus durant la seconde moitié du 19ème siècle, expérience qui sera ensuite reproduite avec succès. Les résultats de cette expérience sont reproduits ci-dessous :
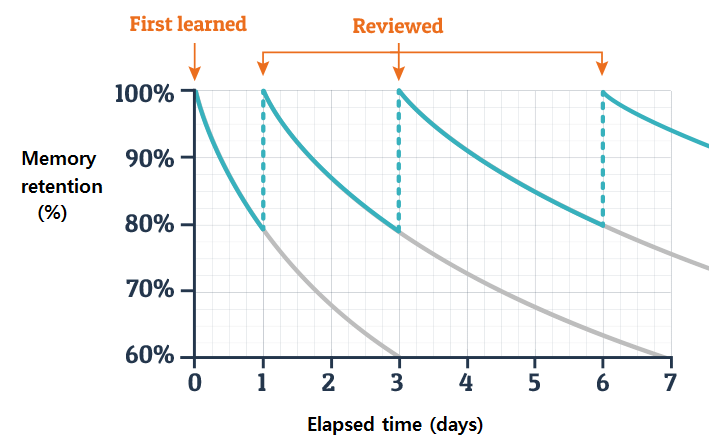
On peut clairement observer, qu’après chaque nouvelle “validation” par la mémoire d’un engramme, la durée de rétention augmente considérablement. Afin de retenir la traduction du mot chat dans la durée, on devrait donc “réviser” cette notion fréquemment, fréquence que l’on pourra abaisser au cours du temps. On parle ici de “spaced repetition”.
On sait sous quelle forme apprendre notre notion, à quelle fréquence la réviser, mais sait-on vraiment comment réviser ? L’erreur la plus classique que l’on fait tous-tes, c’est de simplement relire une liste de choses que l’on voudrait apprendre, dans notre exemple, on relirait la liste des animaux en anglais. Cette façon de réviser est en fait tout à fait inefficace, il est largement préférable de faire ce qu’on appelle en anglais de l’”active recall”, plutôt que de relire notre liste, on va plutôt faire un quizz sur le nom des différents animaux en anglais. Une étude a montré à quel point l’”active recall” est efficace, dans celle-ci un groupe d'étudiants devait apprendre 40 paires de mots de vocabulaire dans une langue étrange, puis a été testé sur l'ensemble de ces paires. Lorsqu'un étudiant se souvient correctement d'un mot et de sa traduction une fois, cette paire de mots était traitée de l'une des quatre manières suivantes :
- L'élève continuait à étudier et à être testé sur les 40 paires de mots.
- L'élève n'étudiait plus ce couple de mots, mais continuait à être testé sur celui-ci.
- L'élève continue à étudier ce couple de mots, mais n'a plus été testé sur celui-ci.
- L'élève n'a plus étudié et n'a plus été testé sur cette paire de mots.
Les élèves sont ensuite revenus une semaine plus tard pour un nouveau test. Les résultats de l’étude sont présents ci-dessous :
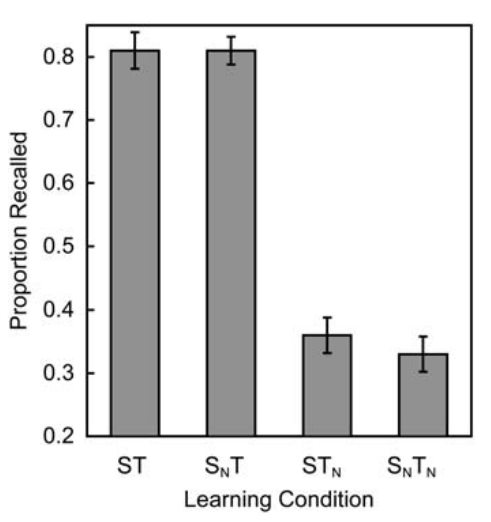
On voit ici très clairement que les élèves ayant eu les meilleurs résultats au test sont ceux ayant révisé en faisant de l’”active recall”.
Nous chercherions donc un logiciel, qui nous permettrait de créer
- Des “quiz” (active recall)
- ... qui contiennent différents types de contenus multimédia (maximiser le nombre de connexion neuronales)
- ... et qui permettrait de revoir à une certaine fréquence, correspondant à la courbe de l’oubli, ces quizz (spaced repetition)
Il existe un outil tout trouvé afin d’accomplir ces taches, Anki que je vais vous présenter dans le prochain article, à paraitre dans une semaine !
🙏 Remerciements
Merci à Paul Frankland d’avoir répondu à mes questions sur les mécanismes de l’oubli et de m’avoir envoyé gratuitement le préprint de son article Forgetting as a form of adaptive engram cell plasticity !
Merci à Jaap Murre d’avoir répondu à mes questions sur son étude sur la réplication de la courbe de l’oubli d’Ebbinghaus !
Merci à Leni/Romain Cazé d’avoir répondu à mes questions sur le fonctionnement biologique de la mémoire et pour sa relecture !
Merci à Ynulpezao d’avoir répondu à mes diverses questions, de m’avoir transmit de nombreuses ressources permettant l’écriture de cet article et pour sa relecture !
Merci à tous-tes les autres contributeur-ices d’I Learned ayant relu cet article !
📚 Références
- Cazé, Romain & Humphries, Mark & Gutkin, Boris. (2012). Spiking and saturating dendrites differentially expand single neuron computation capacity. Advances in neural information processing systems. 25. 1079-1087
- Cazé, Romain & Humphries, Mark & Gutkin, Boris. (2013). Passive Dendrites Enable Single Neurons to Compute Linearly Non-separable Functions. PLoS Computational Biology. 9(2): e1002867
- Citri, A., Malenka, R. Synaptic Plasticity: Multiple Forms, Functions, and Mechanisms. Neuropsychopharmacol 33, 18–41 (2008)
- Murre, J. M. J., & Dros, J. (2015). Replication and Analysis of Ebbinghaus’ Forgetting Curve. In D. R. Chialvo (Éd.), PLOS ONE (Vol. 10, Issue 7, p. e0120644). Public Library of Science (PLoS).
- Ebbinghaus H. (2013). Memory: a contribution to experimental psychology. Annals of neurosciences, 20 (4), 155–156.
- Ryan, T.J., Frankland, P.W. Forgetting as a form of adaptive engram cell plasticity. Nat Rev Neurosci 23, 173–186 (2022).
- Hardt, O., Nader, K., & Wang, Y. T. (2013). GluA2-dependent AMPA receptor endocytosis and the decay of early and late long-term potentiation: possible mechanisms for forgetting of short- and long-term memories. Philosophical transactions of the Royal Society of London. Series B, Biological sciences , 369 (1633), 20130141
- Dong, Z., Han, H., Li, H., Bai, Y., Wang, W., Tu, M., Peng, Y., Zhou, L., He, W., Wu, X., Tan, T., Liu, M., Wu, X., Zhou, W., Jin, W., Zhang, S., Sacktor, T. C., Li, T., Song, W., & Wang, Y. T. (2015). Long-term potentiation decay and memory loss are mediated by AMPAR endocytosis. The Journal of clinical investigation, 125(1), 234–247
- Davis, R. L., & Zhong, Y. (2017). The Biology of Forgetting-A Perspective. Neuron , 95 (3), 490–503.
- Karpicke, J. D., & Henry L. Roediger. (2008). The Critical Importance of Retrieval for Learning. Science, 319(5865), 966–968.
- Harris D M, Chiang M (March 27, 2022) An Analysis of Anki Usage and Strategy of First-Year Medical Students in a Structure and Function Course. Cureus 14(3): e23530
- Chun, Bo Ae & hae ja, Heo. (2018). The effect of flipped learning on academic performance as an innovative method for overcoming ebbinghaus' forgetting curve. 56-60