
Le web est l'usage le plus connu d'internet, un protocole assez vieux (mais pas aussi vieux qu'internet) se cache derrière ce succès : HTTP.
HTTP est l'acronyme d'Hyper Text Transfer Protocol (protocole de transfert hypertexte si l'on traduit en français), il a été inventé pour palier à certains manques de FTP qui à l'époque était majoritaire, un des points principaux est la notion de format de données, c'est à dire indiquer au client quel est le type de donnée, cela permet au client de pouvoir interpréter et afficher sans demander à l'utilisateur ce qu'il doit faire de chaque fichier. Cette notion de "format de données" s'appelle le MIME.
HTTP a connu plusieurs versions, l'initiale étant la 0.9 (notée HTTP/0.9) qui n'a jamais été standardisée dans une RFC, une RFC (pour request for comment, soit demande de commentaires en français) est un document technique identifié par un numéro définissant des procédures ou protocoles, ces documents sont accessibles sur https://www.rfc-editor.org/rfc/ (ou gemini://gemini.bortzmeyer.org/rfc-mirror/rfc-index.gmi via Gemini), l'usage de cette version d'HTTP est assez marginal de nos jours. Quelques années plus tard est sorti au travers d'une RFC (la 1945) HTTP/1.0 cette RFC s'occupe surtout de préciser comment HTTP fonctionne, il n'apporte pas d'évolution avec la version 0.9. Assez rapidement HTTP/1.1 sort, cette version apporte certaines optimisations, comme l'envoi de plusieurs requêtes en simultané.
Le fonctionnement d'HTTP se base sur le protocole TCP, par défaut le port utilisé est le 80. Pour demander ou envoyer des contenus on utilise des "méthodes", une méthode est une commande envoyée au serveur. On peut en citer plusieurs :
- GET : Demande une ressource
- HEAD : Demande uniquement les informations
- POST : Envoie des données
La liste n'est pas complète, je vous laisse rechercher par vous même pour plus d'informations à ce propos ;).
On peut regarder plus en profondeur HTTP en regardant les transmissions réseaux :
 La partie data, celle qui contient la page en elle même n'est pas directement visible ici, je vous laisse regarder le dump réseau sur wireshark, il est disponible ici.
La partie data, celle qui contient la page en elle même n'est pas directement visible ici, je vous laisse regarder le dump réseau sur wireshark, il est disponible ici.
Un autre aspect intéressant d'HTTP sont les en-têtes (headers) qui donnent des informations au client à propos du serveur, et inversement. Côté client par exemple, on a l'en-tête "Host" qui donne le nom de domaine demandé par le client, cela permet de distribuer un contenu différent en fonction de celui-ci. Le serveur peut lui donner le type de contenu via "Content-Type". Il y a beaucoup d'autres en-têtes possibles, si vous voulez regarder celle d'une URL la commande curl le permet via l'option -I, pour https://ramle.be par exemple :
% curl -I https://ramle.be
HTTP/2 200
server: nginx
date: Sat, 08 May 2021 14:40:55 GMT
content-type: text/html; charset=utf-8
content-length: 1992
last-modified: Fri, 23 Apr 2021 18:18:34 GMT
vary: Accept-Encoding
etag: "60830f7a-7c8"
content-security-policy: default-src 'none'; style-src cdn.ramle.be; img-src cdn.ramle.be
x-frame-options: SAMEORIGIN
x-xss-protection: 1; mode=block
x-content-type-options: nosniff
referrer-policy: same-origin
x-permitted-cross-domain-policies: master-only
expect-ct: max-age=60, enforce
permissions-policy: accelerometer=(), camera=(), geolocation=(), gyroscope=(), magnetometer=(), microphone=(), payment=(), usb=()
strict-transport-security: max-age=31536000; includeSubDomains; preload
accept-ranges: bytes
On remarque sur la première ligne la version d'HTTP, ici c'est la version 2. On voit ensuite la liste des en-têtes :
- content-type indique le type de contenu (le MIME)
- etag indique une suite de caractères ASCII, cette chaîne change si le contenu distant change, cela permet de mettre en cache les ressources. Il n'y a pas de méthode définie pour la génération de cette chaîne de caractères.
Je n'ai décrit ici que les en-têtes qui me semblait importants pour cet article, beaucoup d'autres en-têtes restent très utiles mais moins utilisés, souvent orientés sécurité, certains feront surement l'objet d'un article prochainement ;). Si vous voulez des informations plus précises sur celle-ci je vous laisse aller voir la documentation de MDN qui est assez complète.
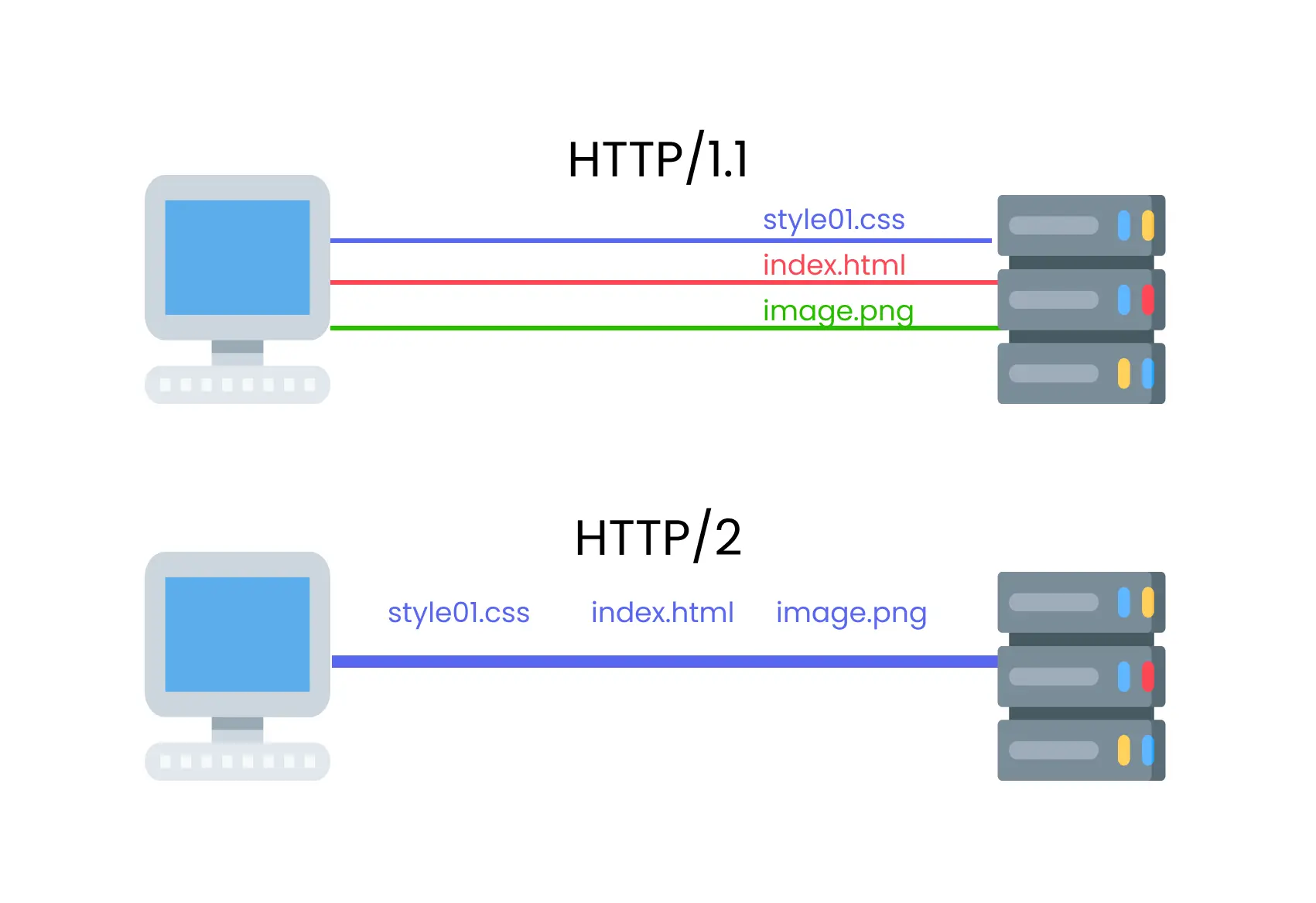
J'ai cité plus haut la version 2 d'HTTP (notée HTTP/2) sans expliquer les changements apportés par cette version, nous allons donc dans ce paragraphe voir les différences avec HTTP/1.1, pour commencer l'implémentation faite par beaucoup de navigateurs impose le chiffrement via HTTPS (on reparlera plus bas d'HTTPS), un autre changement est dans le transport lui même, HTTP/1.1 se base sur du texte, là ou HTTP/2 utilise du binaire, ça le rends plus compact et facile à parser, mais non lisible par un humain sans outil spécifique. Il y a aussi un changement dans la connexion TCP elle même, au lieu de faire une connexion TCP par ressource, on utilise une seule connexion pour toutes les ressources le gain latence est assez important au vu du nombre d'aller-retour TCP.
://
 :
:
Vous avez probablement remarqué qu'HTTP ne présente presque aucun mécanisme de sécurité de base, il n'est en effet pas possible de vérifier l'authenticité des ressources ni d'empêcher un attaquant d'espionner la connexion, pour résoudre ce problème HTTPS est né, il s'agit simplement de faire passer HTTP via TLS, pour ce qui est de la vérification on se base sur les autorités de certification, contrairement à d'autres protocoles comme Gemini, je vous invite à aller voir l'article sur DANE pour plus de détails à propos des autorités de certification.
HTTP permet de réduire la taille des données envoyées en les compressant, les deux algorithmes utilisés pour compresser les données sont gzip et brotli, le client peut dire au serveur lequel de ces algorithmes il supporte via l'en-tête "Accept-encoding".
C'est tout pour l'article d'aujourd'hui, j'espère qu'il vous aura plus :), On se retrouve demain pour parler de radvd.