
De plus en plus de navigateurs mettent en place des mesures pour bloquer le tracking, Firefox par exemple, bloque par défaut les cookies third party. Pour contourner ces mesures de protection des utilisateurs, les entreprises de tracking sont à la recherche d'autres moyens de pister les utilisateurs, ETag est l'un d'eux. Nous en avons brièvement parlé dans l'article sur HTTP, l'en-tête ETag est dans le cas du serveur web Nginx que nous prendrons comme exemple ici, un condensat de la date de modification et de la longueur (lenght) du fichier demandé. Ce hash a été créé pour permettre au navigateur de savoir s'il y a eu des changements sur un fichier et s'il doit montrer la version du fichier conservée en cache à l'utilisateur ou télécharger à nouveau le fichier depuis le serveur.
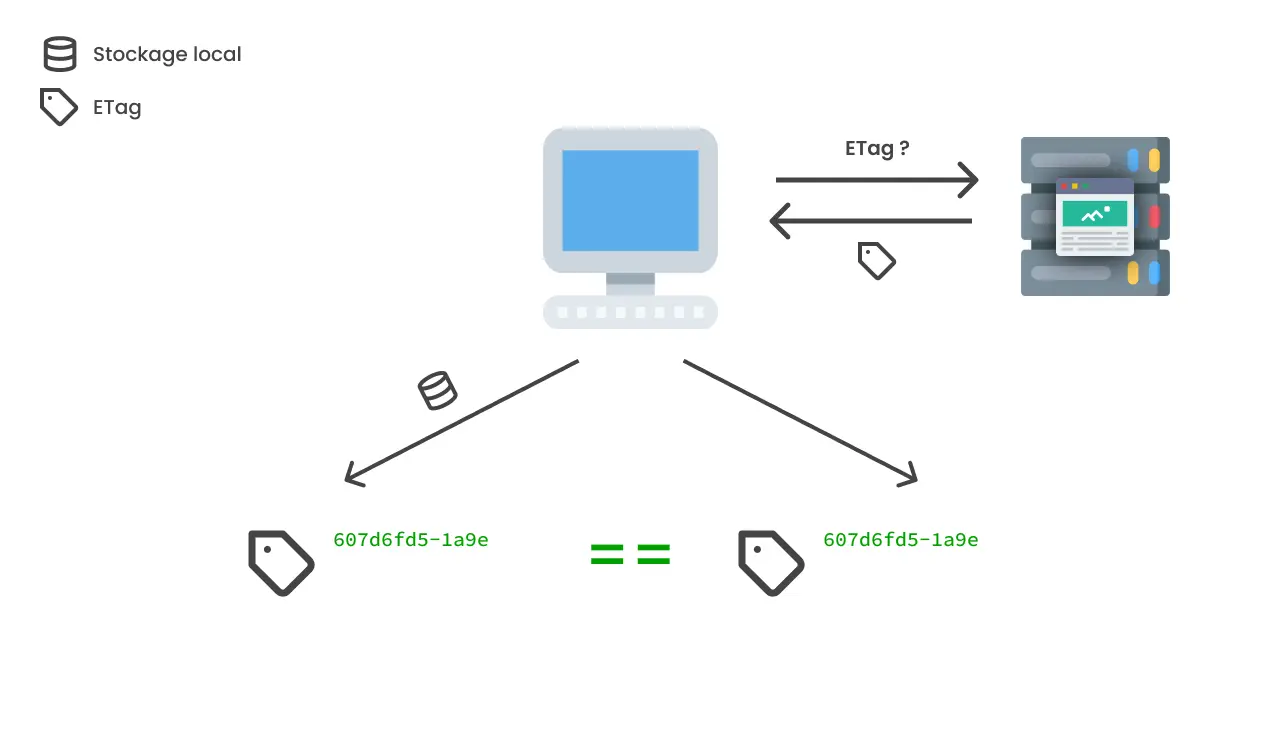
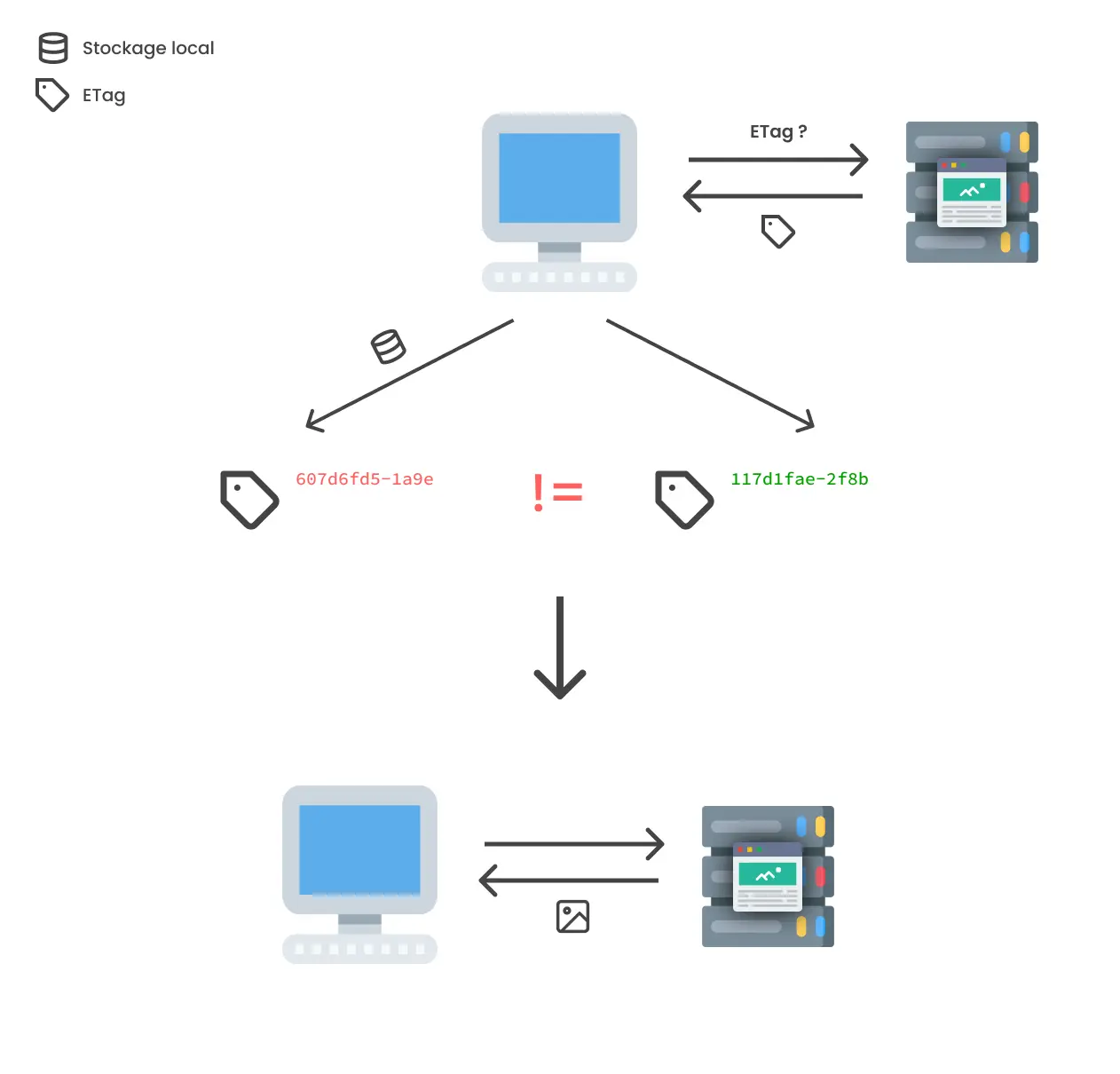
Ce système d'ETag peut cependant être détourné, afin de vérifier si les ETag correspondent, le client envoie l'ETag de la version qu'il a du fichier au serveur, le serveur peut donc, pour chaque utilisateur, servir un fichier différent (qui aura donc un ETag différent) et grâce à cet ETag savoir quel utilisateur a consulté quelle page à quelle moment. Des entreprises comme Hulu ou Spotify ont été épinglées pour avoir mis en place cette pratique, qui ne respecte évidemment pas le RGPD.
![]()
Merci d'avoir lu cet article, en espérant qu'il a été clair :) On se retrouve demain pour parler de décentralisation !