
Dans cet article je vais vous parler de la compilation d'un programme informatique, quelles sont ses "phases" et leurs utilité, et tout ce qui se cache derrière tout ça.
Initialement cet article devait traiter de la compilation, de l'interprétation et de la semi interprétation, mais il y'a tellement de chose à dire que vous parler de tout ce bon monde dans un seul est unique article serait un enfer pour vous, alors j'ai décidé de faire un article pour chacun de ces sujets.
La Compilation
Alors, premièrement qu'est ce que c'est la compilation ?
La compilation permet, en bref, de transformer/traduire le code source d'un programme en langage machine pour qu'il puisse être exécuté par votre processeur.
Pourquoi ne pas directement progammer en langage machine alors ?
Je pense que vous êtes des êtres humains (sinon faudrait complètement revoir nos statistiques sur le blog). Le langages machine, comme son nom l'indique, c'est du langage pour la machine, et vous en ête pas une ... ~~en tout cas pas encore~~ il vous faut donc une alternative au langage machine pour nous, un langage qui se rapproche du language humain pour que ce soit plus simple de lire et/ou écrire du code.
Le premier language créé pour "humaniser" le langage machine, c'est le langage d'assemblage ou plus couramment dit: "language d'assembleur". Voici un exemple du fameux "Hello world !" en language d'assembleur sous Linux 64bits
bits 64
global main
section .data
Hello db "Hello world !", 10, 0
section .text
main:
push rbp
mov rbp, rsp
mov rax, 1 ; syscall write
mov rdi, 1 ; stdout
mov rsi, Hello
mov rdx, 15 ; size of "Hello world!\n" + nullbyte
syscall
leave
Je ne vais pas vous expliquer qui fait quoi dans ce code, les commentaires reste assez explicite et de toute façon ce n'est pas l'objet de cet article.
Et le language machine correspondant (de la section main) ressemble à ceci:
55
48 89 e5
b8 01 00 00 00
bf 01 00 00 00
48 be 28 40 40 00 00
ba 0f 00 00 00
0f 05
c9
Vous voyez c'est le jour et la nuit, même si le language d'assemblage reste assez austere, ca reste humainement plus lisible que du language machine.
Languages moderne
Heureusement aujourd'hui les languages de programmation ont changé notamment grace à la venue du language B dont le language C s'est inspiré et qui a ensuite inspiré quasiment tout les autres languages suivant celui-ci. Si vous jettez un oeil aux langages précédant le langage B ; Fortran, Cobol, vous remarquez qu'ils restent plus ou moins similaires au language d'assembleur.
Exemple de "Hello world !" en C:
#include <stdio.h>
int main() {
printf("Hello world !");
return 0;
}
C'est tout de suite plus agréable que le language d'assembleur !
Les étapes de la compilation
Bon, maintenant que vous avez compris que c'était plus drôle d'écrire avec un language autre que le language machine, je vais vous parler des différentes phases de la compilation.
Les 3 plus grosses phases (les plus souvents présentées dans les schémas) sont:
- La phase préprocesseurs
- La compilation
- L'édition de liens
Ce sont les plus grosses étapes, mais il y'en a d'autres.. pleins d'autres qui se passent avant, pendant et après ces 3 là.
Le prétraitement
Cette phase permet de substituer des macros dans le code. Prenons les exemples suivants
#include <stdio.h>
#define TOTO 42
Lors de cette phase, tout le contenu du fichier stdio.h est inséré dans le fichier source.
Tous les TOTO sont remplacés par 42.
Il existe aussi des préprocesseurs "conditionnels" (if, else, ...) qui sont souvent utilisés, par exemple lorsque le programme est en developpement on peut écrire des macros qui permettent d'ajouter du code pour faciliter le débug du programme, mais lors de la publication de la version "finale" du programme, on peut ommetre certains codes pour ne pas surcharger le code source avec du code en plus.
Exemple:
#if DEBUG
assert(var == false)
assert(var2 > var3)
printf("Tout est correct");
#endif
Si lors de la compilation on spécifie la macro DEBUG le code au dessus sera pris en compte dans le code source.
Mais si on ne spécifie pas cette macro, la phase de prétraitement passera outre ce code la.
L'analyse lexicale
Et oui, très souvent oublié dans les petits schémas récapitulatifs, il y'a une analyse lexicale. Elle est réalisée en parcourant le code source en une seul fois.
Cette phase permet de verifier si les mots existent dans le language et à quel unité de lexique ils appartiennent puis les "découpes" de sorte à former des "token".
Unité de lexique
- identifiants:
une_variable,une_fonction,x, etc... - mots-clefs:
if,while,return,for,extern,auto,static, etc... - ponctuation:
},(,; - opérateurs:
+,<,=,<=,==, etc... - littéraux
42,69.0f,"hello",0xb00b
Une fois l'analyse lexicale faites les "tokens" sont générés. Par exemple, prenont le code suivant:
int ma_variable = 32 + 8 + 2;
On se retrouve avec les tokens suivant:
int : mot-clef du type entier
ma_variable : identifiant
= : opérateur d'affectation
32 : entier littéral
+ : opérateur d'addition
8 : entier littéral
+ : opérateur d'addition
2 : entier littéral
; : fin de l'initialisation
Dans l'analyse lexicale il se passe encore plein d'autre chose comme le "balayage" et "L'évaluation" mais qui sont justes des étapes intermédiaires pour arriver à l'objectif de l'analyse léxicale.
En conclusion, l'analyseur lexical vérifie si les mots existent bien et les transforme en token pour l'analyseur syntaxique.
Par exemple en language Francais: Loubala n'est pas correcte, ce mot n'existe pas dans la langue Française.
L'analyse syntaxique
L'analyse syntaxique suit directement l'analyse lexicale et permet de vérifier si les mots/groupes de mots forment des "phrases" conforme du language en analysant les tokens générer par l'analyse lexicale.
Si on reprend l'exemple avec le Francais: Manger boire.
Cette suite de mot est lexicalment correct, ces mots existent dans la langue Française, mais synaxiquement fausse car ils ne forment pas une phrase correct en Francais.
L'analyseur syntaxique genère un arbre de syntaxe abstraite (ASA) qui sera utilisé pour l'analyse sémantique.
Arbre de syntaxe abstraite
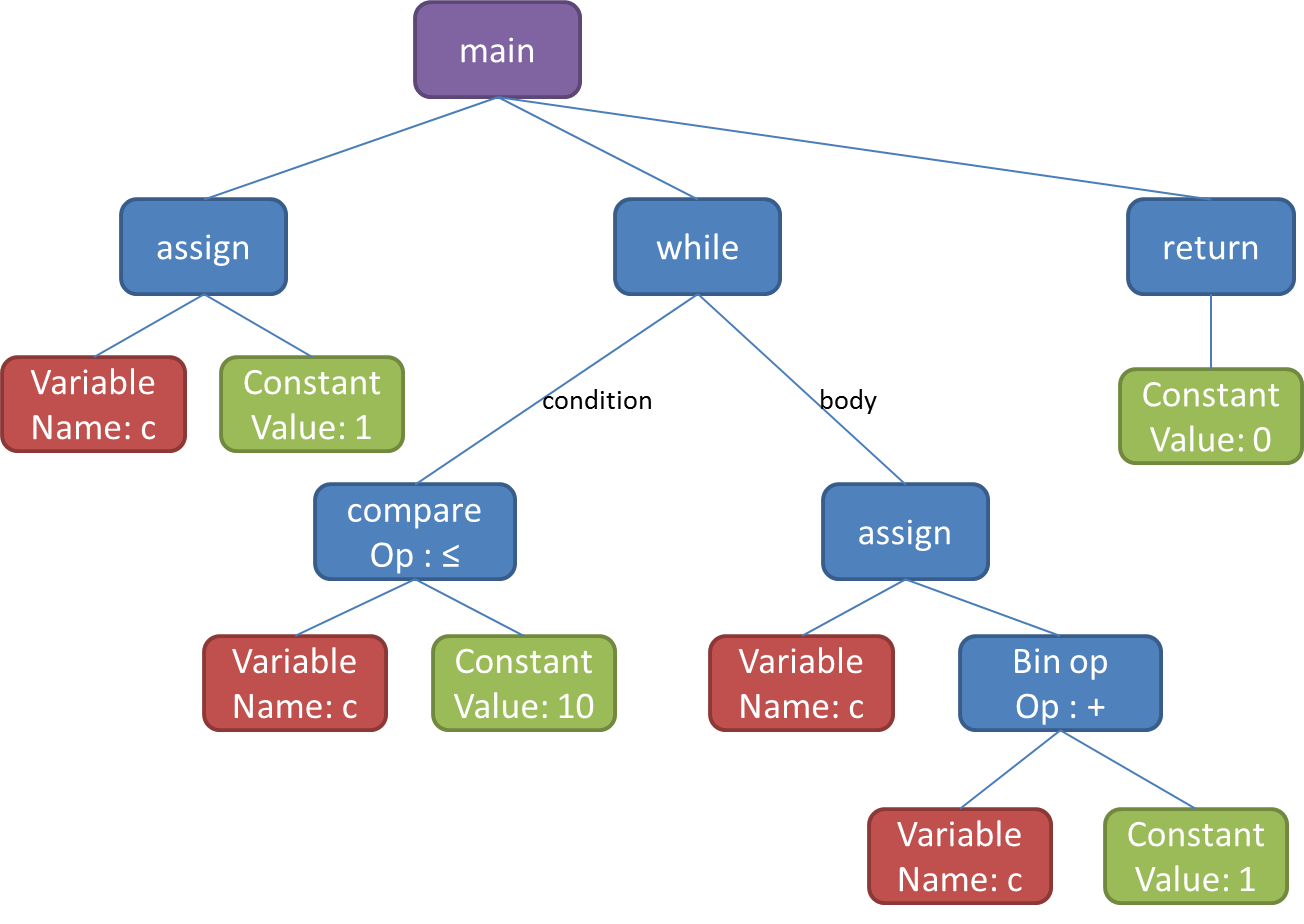
Analyse sémantique
Cette phase suit immediatement l'analyse syntaxique. Ici, on analyse l'ASA fourni par l'analyseur syntaxique. L’objectif de cette phase est de vérifier que toutes les phrases écrites dans l’ASA ont un sens dans le language utilisé.
Par exemple dans la langue Francaise: L'avion manges des fruits.
- Le lexique est correct, chaques mots utilisé existent dans la langue Francaise.
- La syntaxe est également correcte, c'est une phrase conforme à la langue Francaise.
- Mais sémantiquement fausse car la phrase ne veut rien dire.
C'est lors de l'analyse sémantique que le compilateur génère la table des symboles qui permet, dans les grandes lignes, de ranger les identificateur avec leur type, l'emplacement mémoire, la portée, la visibilité, etc.
Three Address Code
Le "Thee Address Code" (TAC) est une optimisation de compilation qui permet de traduire chaque instruction en maximum 3 opérandes (comme en language d'assembleur).
Par exemple, si on reprend le code suivant:
ma_variable = 32 + 8 + 2
en TAC cela donnerait:
t1 = 32 + 8
t2 = t1 + 2
ma_variable = t2
L'optimisation du code
Ici le code est optimisé (il peut aussi l'êtres avant la génération de code intermédaire 'TAC')
Language Assemblage
Le code est ensuite traduit en langage d'assembleur (qu'on a vu dans la première section de cet article)
Assembleur
Avant dernière étape, le langage d'assembleur est ensuite passé à un suspense assembleur pour être re suspense assemblé !
Ce qui nous donne un fichier "objet" contenant du code machine.
Édition de lien
Enfin nous voila à la dernière étape ! L'édition de lien.
Cette étape permet de lier plusieur fichiers objet qui on été générés par le compilateur.
Quand un programme dépend d'autre fichier, notamment de la librairie standard du language (la libc par exemple), il faut spécifier à votre programme où se trouve le code de printf ou fgets ou tout autre fonction se trouvant dans la librairie standard, car ce que vous incluez avec le préprocesseurs include c'est juste les déclaration des fonctions et autre macro, donc votre main a connaissance de la fonction printf il sait qu'elle type de donnée la fonction retourne, le type et nombre d'arguments que la fonction a besoin, mais vous n'avez pas le code de la fonction, le code est dans la librairie libc.
Il faut donc lier cette librarire a votre programme et cela ce fait avec l'éditeur de lien.
Schéma récapitulatif
En résumé nous avons ce schéma:

C'est fini pour cet article, j'espère qu'il vous a plu, je pense avoir parlé du plus important, il se passe bien évidemment d'autre chose lors de la compilation mais c'est plus pour de l'optimisation ou parce que le language utilise des choses plus complexes comme le polymorphisme avec les templates ou les fonctions inlines etc (qui sont comme des macro-fonctions mais substitué lors de la compilation et non lors de la phase prétraitement). Mais j'estime avoir parlé du plus important et du plus basique.